再研究完dispatch_queue之后,本来是打算进入到dispath_group的源码,但是dispath_group基本是围绕着dispatch_semaphore即信号量实现的,所以我们先进入到dispatch_semaphore的源码学习。在GCD中使用dispatch_semaphore用来保证资源使用的安全性(队列的同步执行就是依赖信号量实现)。可想而知,dispatch_semaphore的性能应该是不差的。
dispatch_semaphore_t
dispatch_semaphore_s是信号量的结构体。代码如下:
1 | struct dispatch_semaphore_s { |
虽然上面还有一些属性不知道是做什么作用的,但我们继续往下走。
dispatch_semaphore_create
dispatch_semaphore_create用于信号量的创建。
1 | dispatch_semaphore_t |
上面的源码中dsema->do_vtable = &_dispatch_semaphore_vtable;
_dispatch_semaphore_vtable定义如下:
1 | const struct dispatch_semaphore_vtable_s _dispatch_semaphore_vtable = { |
这里有个_dispatch_semaphore_dispose函数就是信号量的销毁函数。代码如下:
1 | static void |
dispatch_semaphore_wait
创建好一个信号量后就会开始进入等待信号发消息。
1 | long |
_dispatch_semaphore_wait_slow
在dispatch_semaphore_wait中,如果value小于0,就会执行_dispatch_semaphore_wait_slow等待信号量唤醒或者timeout超时。_dispatch_semaphore_wait_slow的代码如下:
1 | static long |
在上面的源码还有几个地方需要注意:
第一部分的那个while循环和if条件。在
dsema_sent_ksignals非0的情况下便会进入while循环,if的条件是dsema->dsema_sent_ksignals如果等于orig,则将orig - 1赋值给dsema_sent_ksignals,并且返回true,否则返回false。很明显,只要能进入循环,这个条件是一定成立的,函数直接返回0,表示等到信号。而在初始化信号量的时候没有对dsema_sent_ksignals赋值,所以就会进入之后的代码。也就是说没有信号量的实际通知或者遭受了系统异常通知,并不会解除等待在上面中出现了
semaphore_timedwait和semaphore_wait。这些方法是在semaphore.h中的。所以说dispatch_semaphore是基于mach内核的信号量接口实现的。另外这两个方法传入的参数是dsema_port即dsema_port被mach内核semaphore监听,所以我们理解dsema_port是dispatch_semaphore的信号。我们回过头再看一下
dispatch_semaphore_s结构体中的dsema_waiter_port。全局搜索一下可以发现,这个属性是用在dispatch_group中。之前也说了dispatch_group的实现是基于dispatch_semaphore,在dispatch_group里semaphore_wait监听的并不是dsema_port而是dsema_waiter_port。
dispatch_semaphore_wait流程如下图所示: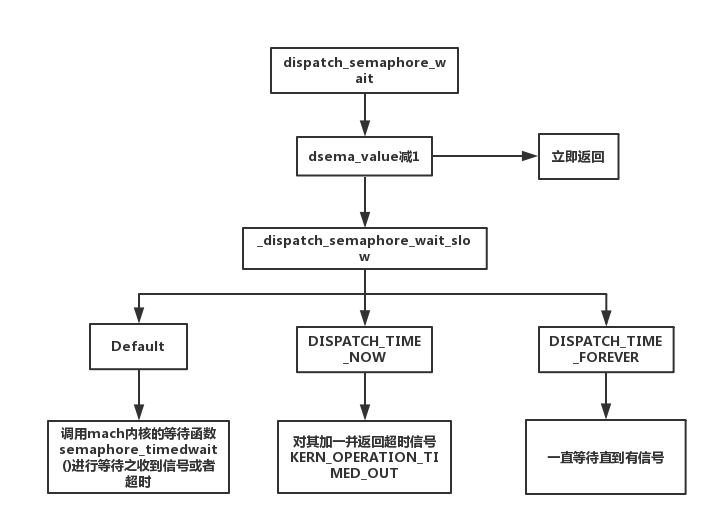
dispatch_semaphore_signal
发送信号的代码相对等待信号来说简单很多,它不需要阻塞,只发送唤醒。
1 | long |
_dispatch_semaphore_signal_slow
1 | long |
_dispatch_semaphore_signal_slow的作用就是内核的semaphore_signal函数唤醒在dispatch_semaphore_wait中等待的线程量,然后返回1。
dispatch_semaphore_signal流程如下图所示: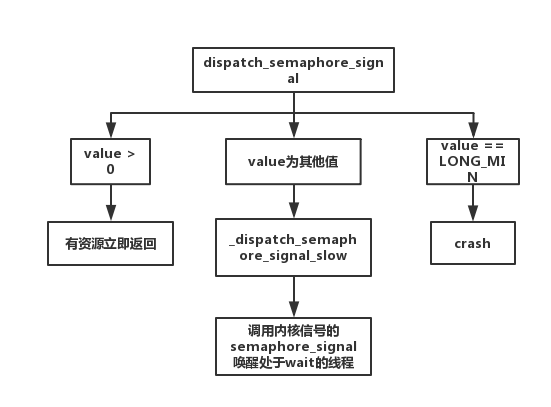
总结
dispatch_semaphore是基于mach内核的信号量接口实现的调用
dispatch_semaphore_wait信号量减1,调用dispatch_semaphore_signal信号量加1在
wait中,信号量大于等于0代表有资源立即返回,否则等待信号量或者返回超时;在signal中,信号量大于0代表有资源立即返回,否则唤醒某个正在等待的线程dispatch_semaphore利用了两个变量desma_value和dsema_sent_ksignals来处理wait和signal,在singnal中如果有资源,则不需要唤醒线程,那么此时只需要使用desma_value。当需要唤醒线程的时候,发送的信号是dsema_sent_ksignals的值,此时会重新执行wait的流程,所以在wait中一开始是用dsema_sent_ksignals做判断。再看一下
dispatch_semaphore_s结构体的变量。
1 | struct dispatch_semaphore_s { |
补充
如何控制线程并发数
方法1:使用信号量进行并发控制
1 | dispatch_queue_t concurrentQueue = dispatch_queue_create("concurrentQueue", DISPATCH_QUEUE_CONCURRENT); |
结果
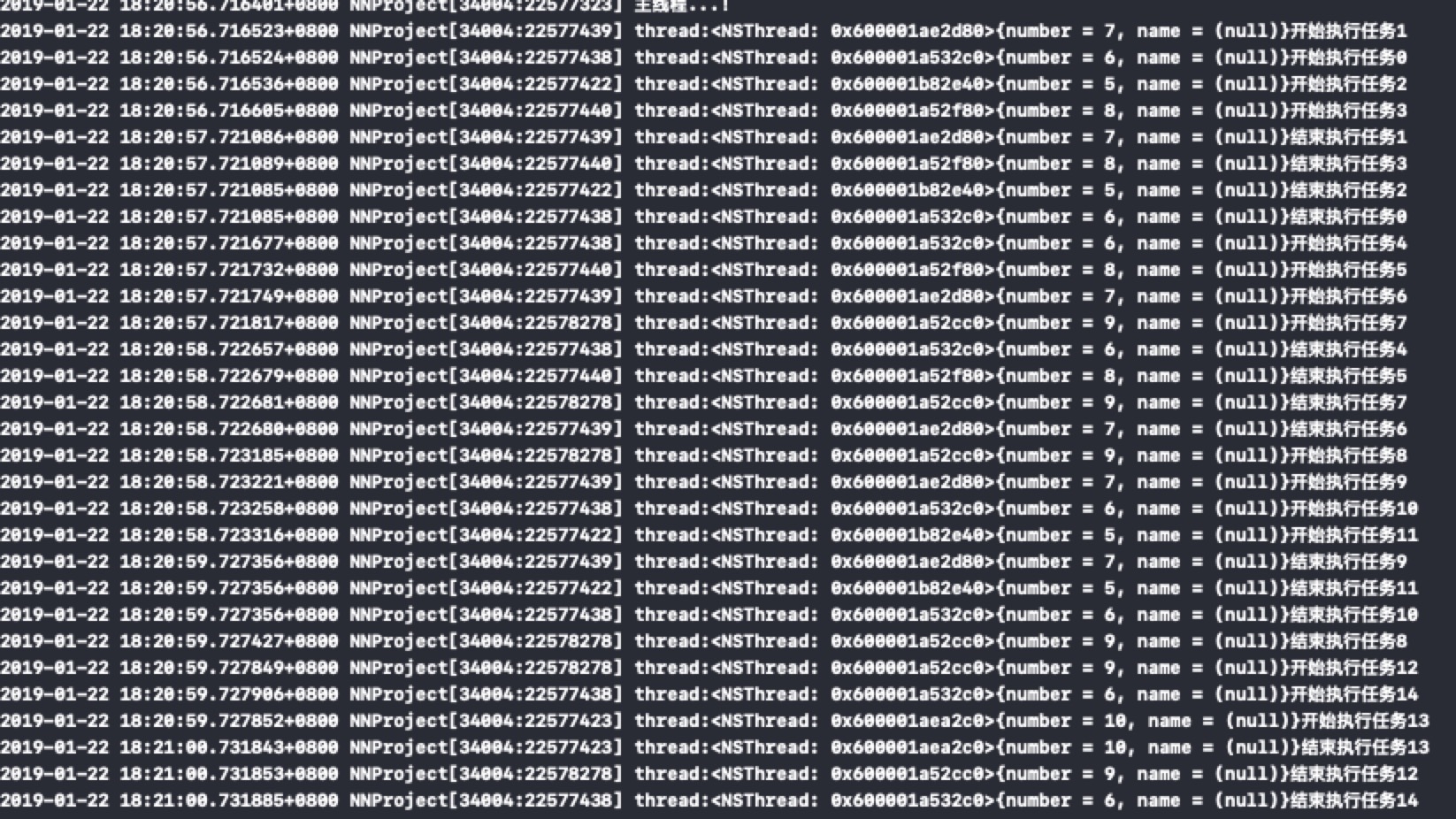
方法2:YYDispatchQueuePool的实现思路
YYKit组件中的YYDispatchQueuePool也能控制并发队列的并发数
在iOS保持界面流畅的技巧原文中提到:
其思路是为不同优先级创建和 CPU 数量相同的 serial queue,每次从 pool 中获取 queue 时,会轮询返回其中一个 queue。我把 App 内所有异步操作,包括图像解码、对象释放、异步绘制等,都按优先级不同放入了全局的 serial queue 中执行,这样尽量避免了过多线程导致的性能问题。