更新于2020-12-13 更新异步执行任务的源码分析
GCD队列是我们在使用GCD中经常接触的技术点,分析dispatch_queue部分的源码能更好得理解多线程时的处理。但是libdispatch的源码相对来说比较复杂,综合考虑下,使用了libdispatch-187.9进行分析。
队列和线程的关系
Concurrent Programming: APIs and Challenges中的一张图片可以很直观地描述GCD与线程之间的关系: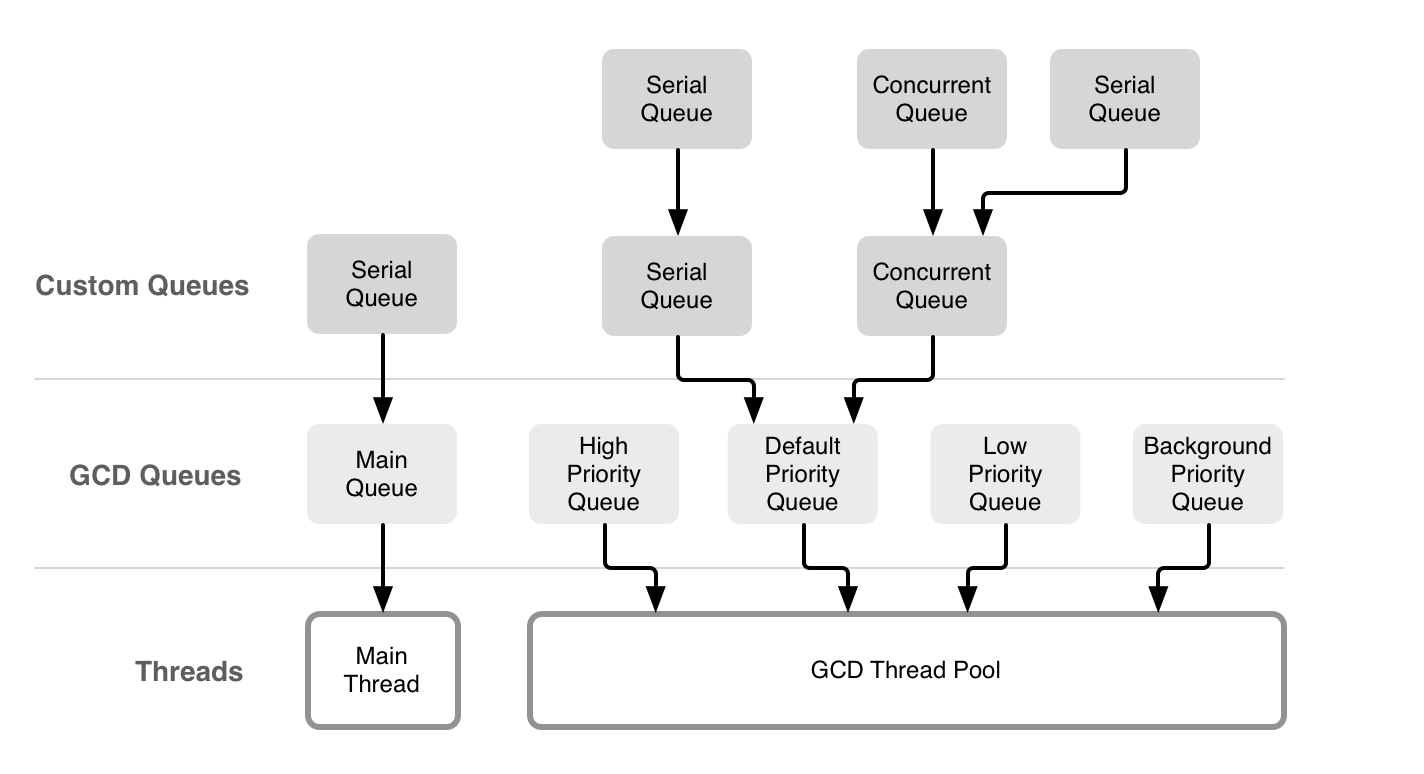
线程和队列并不是一对一的关系,一个线程内可能有多个队列,这些队列可能是串行的或者是并行的,按照同步或者异步的方式工作。
对于主线程和主队列来说,主队列是主线程上的一个串行队列,是系统自动为我们创建的,换言之,主线程是可以执行除主队列之外其他队列的任务。我们可以用下面一段代码进行测试:
1 | // 测试代码 |
队列的定义
dispatch_queue_s
dispatch_queue_s是队列的结构体,可以说我们在GCD中接触最多的结构体了。GCD中使用了很多的宏,不利于我们理解代码,我们用对应的结构替换掉定义的宏。
为了方便后续的分析,先列出一些函数方便后面的理解
1 | struct dispatch_queue_s { |
dispatch_queue_vtable_s
在GCD队列中,dispatch_queue_vtable_s这个结构体内包含了dispatch_object_s的操作函数,而且针对这些操作函数,定义了相对简短的宏,方便调用。
1 | // dispatch_queue_vtable_s结构体,声明了一些函数用于操作dispatch_queue_s结构体 |
在queue.c中定义三个关于dispatch_queue_vtable_s的静态常量,分别是1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// 用于主队列和自定义队列
const struct dispatch_queue_vtable_s _dispatch_queue_vtable = {
.do_type = DISPATCH_QUEUE_TYPE,
.do_kind = "queue",
.do_dispose = _dispatch_queue_dispose,
.do_invoke = NULL,
.do_probe = (void *)dummy_function_r0,
.do_debug = dispatch_queue_debug,
};
// 用于全局队列
static const struct dispatch_queue_vtable_s _dispatch_queue_root_vtable = {
.do_type = DISPATCH_QUEUE_GLOBAL_TYPE,
.do_kind = "global-queue",
.do_debug = dispatch_queue_debug,
.do_probe = _dispatch_queue_wakeup_global,
};
// 用于管理队列
static const struct dispatch_queue_vtable_s _dispatch_queue_mgr_vtable = {
.do_type = DISPATCH_QUEUE_MGR_TYPE,
.do_kind = "mgr-queue",
.do_invoke = _dispatch_mgr_thread,
.do_debug = dispatch_queue_debug,
.do_probe = _dispatch_mgr_wakeup,
};
队列的类型
队列的类型可以分为主队列、管理队列、自定义队列、全局队列4种类型。
主队列
使用dispatch_get_main_queue()可获取主队列,它的定义如下:
1 |
|
do_vtable
主队列的do_vtable为_dispatch_queue_vtable。
do_targetq
do_targetq即目标队列,关于目标队列的意义,在分析全局队列的do_targetq中会给一个比较具体的总结。
主队列的目标队列定义:1
2
3
4
5
6
7
8
9
10
11
12[DISPATCH_ROOT_QUEUE_IDX_DEFAULT_OVERCOMMIT_PRIORITY] = {
.do_vtable = &_dispatch_queue_root_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_suspend_cnt = DISPATCH_OBJECT_SUSPEND_LOCK,
.do_ctxt = &_dispatch_root_queue_contexts[
DISPATCH_ROOT_QUEUE_IDX_DEFAULT_OVERCOMMIT_PRIORITY],
.dq_label = "com.apple.root.default-overcommit-priority",
.dq_running = 2,
.dq_width = UINT32_MAX,
.dq_serialnum = 7,
}
do_ref_cnt、do_xref_cnt
do_ref_cnt和do_xref_cnt是引用计数,它们和GCD对象的内存管理相关。主队列的这两个值为DISPATCH_OBJECT_GLOBAL_REFCNT。
1 | void dispatch_retain(dispatch_object_t dou) { |
从上面这几个函数可以看出:
- 主队列的生命周期是伴随着应用的,不会受retain和release的影响。
- 当
do_ref_cnt、do_xref_cnt这两个值同时为0的时候,对象才会被释放。
管理队列
管理队列是GCD的内部队列,不对外公开,这个队列应该是用来扮演管理的角色,GCD定时器就用到了管理队列。
1 | struct dispatch_queue_s _dispatch_mgr_q = { |
do_vtable
管理队列的do_vtable为_dispatch_queue_mgr_vtable。
do_targetq
管理队列的目标队列:1
2
3
4
5
6
7
8
9
10
11
12[DISPATCH_ROOT_QUEUE_IDX_HIGH_OVERCOMMIT_PRIORITY] = {
.do_vtable = &_dispatch_queue_root_vtable,
.do_ref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_xref_cnt = DISPATCH_OBJECT_GLOBAL_REFCNT,
.do_suspend_cnt = DISPATCH_OBJECT_SUSPEND_LOCK,
.do_ctxt = &_dispatch_root_queue_contexts[
DISPATCH_ROOT_QUEUE_IDX_HIGH_OVERCOMMIT_PRIORITY],
.dq_label = "com.apple.root.high-overcommit-priority",
.dq_running = 2,
.dq_width = UINT32_MAX,
.dq_serialnum = 9,
}
do_ref_cnt、do_xref_cnt
管理队列的这两个值为DISPATCH_OBJECT_GLOBAL_REFCNT,所以和主队列的生命周期应该是一样的。
自定义队列
使用dispatch_queue_create(const char *label, dispatch_queue_attr_t attr)创建一个自定义的队列。它的源码如下:
1 | dispatch_queue_t dispatch_queue_create(const char *label, dispatch_queue_attr_t attr) { |
slowpath(x)、fastpath(x)
1 |
fastpath(x)表示x的值极大概率为1,即多数情况下会发生。slowpath(x)表示x的值极大概率为0,即多数情况下不会发生。__builtin_expect来帮助程序员处理分支预测,优化程序,这个函数的语义是:我期望表达式的值等于常量C,编译器应当根据我提供的期望值进行优化。
do_vtable
与主队列一样,自定义队列的do_vtable也是_dispatch_queue_vtable。
do_targetq
自定义队列的目标队列有两种:
- 如果是串行队列,则使用
_dispatch_get_root_queue(0, true)函数获取目标队列,获取到的目标队列是_dispatch_root_queues[DISPATCH_ROOT_QUEUE_IDX_DEFAULT_OVERCOMMIT_PRIORITY]。 - 如果是并发队列,则使用
_dispatch_get_root_queue(0, false)函数获取目标队列,获取到的目标队列是_dispatch_root_queues[DISPATCH_ROOT_QUEUE_IDX_DEFAULT_PRIORITY]。
_dispatch_get_root_queue(long priority, bool overcommit)函数的overcommit参数代表队列在执行block时,无论系统多忙都会新开一个线程,这样做的目的是不会造成某个线程过载。
dq_serialnum
dq_serialnum是在_dispatch_queue_serial_numbers基础上进行原子操作加1,即从12开始累加。1到11被保留的序列号定义如下:
1 | // skip zero |
其中1用于主队列,2用于管理队列,3暂时没有被使用,4~11是用于全局队列的。由于看的源码版本比较老了,后面苹果有新增了几个队列。
全局队列
上面说了很多全局队列,现在我们来看一下全局队列是如何定义的。
1 | dispatch_queue_t dispatch_get_global_queue(long priority, unsigned long flags) { |
do_vtable
全局队列的do_vtable为_dispatch_queue_root_vtable。前面提到_dispatch_queue_root_vtable的检测函数(do_probe)为_dispatch_queue_wakeup_global,这个函数用来唤醒全局队列,具体的后面分析队列唤醒的时候再讲。
do_targetq
无论是主队列、管理队列还是自定义队列,它们都使用了全局队列(就是从root queue中获取的)作为目标队列,但是全局队列并没有设置do_targetq。
在Concurrent Programming: APIs and Challenges提到:
While custom queues are a powerful abstraction, all blocks you schedule on them will ultimately trickle down to one of the system’s global queues and its thread pool(s).
虽然自定义队列是一个强大的抽象,但你在队列上安排的所有Block最终都会落到系统的某一个全局队列及其线程池中。那也就是说GCD用到的queue,无论是自定义队列,或是获取系统的主队列、全局队列、管理队列,其最终都是落脚于GCD root queue中。GCD管理的也不过这些root queue。
do_ref_cnt、do_xref_cnt
管理队列的这两个值为DISPATCH_OBJECT_GLOBAL_REFCNT,所以和主队列的生命周期应该是一样的。
do_ctxt
全局队列中有一个上下文的属性,用来存储线程池相关数据,比如用于线程挂起和唤醒的信号量、线程池尺寸等。它的定义如下:
1 | static struct dispatch_root_queue_context_s _dispatch_root_queue_contexts[] = { |
队列的同步:dispatch_sync分析
测试代码
1 | // 串行队列 |
执行结果1
2
3
4
5
6
7
8
9
101
2:<NSThread: 0x600002478980>{number = 1, name = main}
3
4:<NSThread: 0x600002478980>{number = 1, name = main}
5
1
2:<NSThread: 0x600002478980>{number = 1, name = main}
3
4:<NSThread: 0x600002478980>{number = 1, name = main}
5
虽然省略主队列和全局队列的测试,但是结果是一样的。队列同步执行任务的过程,是不会开辟新的线程,所有任务在当前线程中执行,且会阻塞线程。
入口函数:dispatch_sync
dispatch_sync的源码如下:
1 | void dispatch_sync(dispatch_queue_t dq, void (^work)(void)) { |
_dispatch_sync_slow函数内部也是执行dispatch_sync_f函数,所以dispatch_sync的调用本质即dispatch_sync_f函数。
1 | void dispatch_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func) { |
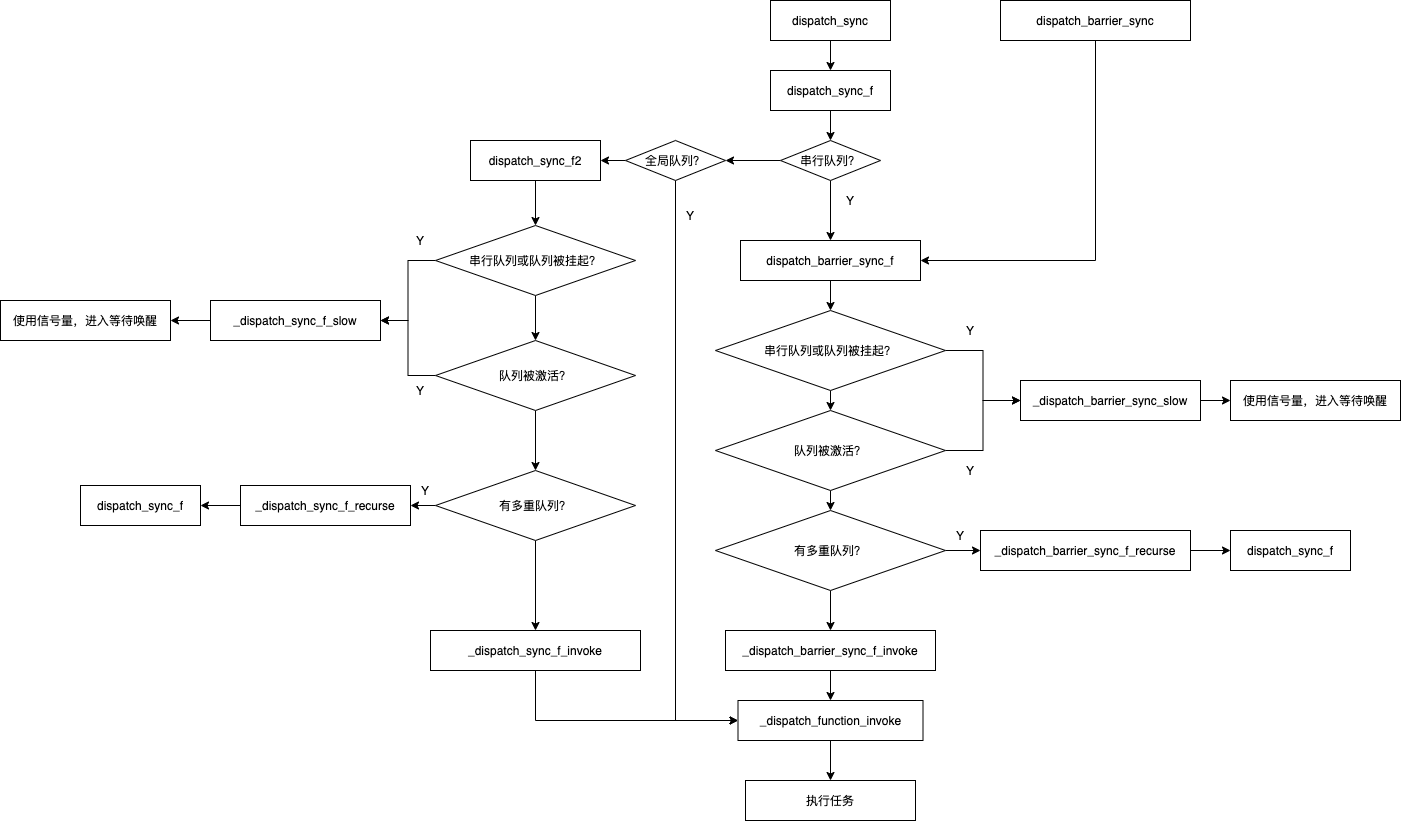
同步执行任务的时候分成了三种情况:
- 如果是串行队列,执行
dispatch_barrier_sync_f即栅栏同步函数; - 如果是全局队列,执行
_dispatch_sync_f_invoke; - 如果是其他队列,执行
_dispatch_sync_f2。
重点函数:dispatch_barrier_sync_f
在分析dispatch_barrier_sync_f这个函数前,我们看一下dispatch_barrier_sync函数即同步栅栏函数。它的实现如下:
1 | void dispatch_barrier_sync(dispatch_queue_t dq, void (^work)(void)) { |
它的底层也是调用dispatch_barrier_sync_f函数。如果是串行队列压入同步任务,那么当前任务就必须等待前面的任务执行完成后才能执行,源代码就会调用dispatch_barrier_sync_f函数完成上面的效果。
1 | DISPATCH_NOINLINE |
这里涉及到三个函数:
_dispatch_barrier_sync_f_slow函数内部使用了线程对应的信号量并且调用wait方法_dispatch_barrier_sync_f_recurse函数内部调用了dispatch_sync_f函数,还是在寻找真正的目标队列- 如果队列无任务执行,调用
_dispatch_barrier_sync_f_invoke执行任务。执行任务的时候会调用_dispatch_function_invoke函数。
_dispatch_barrier_sync_f_invoke
1 | DISPATCH_NOINLINE |
GCD死锁
看了上面的代码注释后,我们来想一下死锁是怎么产生的?先看下示例代码:
1 |
|
以_serialQueueDeadLock为例:当第一次执行串行队列任务的时候,跳到第4步,直接开始执行任务,在运行第二个dispatch_sync时候,在任务里面通过执行第1步(队列在运行)向这个同步队列中压入信号量,然后等待信号量,进入死锁。
以_mianQueueDeadLock为例:主队列则会跳转到第2步进入死锁。
_dispatch_sync_f_invoke
如果当前队列是全局队列的话,就会调用_dispatch_sync_f_invoke函数。
1 | static void |
这个函数的作用:通过_dispatch_function_invoke函数执行传入的任务,然后根据dq_running检测任务队列有没有激活,没有激活就执行激活函数。关于激活函数_dispatch_wakeup(dq)放在队列的异步中讲解。
重点函数:_dispatch_sync_f2
根据前面讲到的,如果是其他队列,执行_dispatch_sync_f2。这个其他队列我们可以认为就是自定义的并行队列。
1 | _dispatch_sync_f2(dispatch_queue_t dq, void *ctxt, dispatch_function_t func) { |
这里涉及到三个函数:
_dispatch_sync_f_slow函数内部使用了线程对应的信号量并且调用wait方法。_dispatch_sync_f_recurse函数内部调用了dispatch_sync_f函数,还是在寻找真正的目标队列。- 如果队列无任务执行,调用
_dispatch_sync_f_invoke执行任务。执行任务的时候会调用_dispatch_function_invoke函数。
通过上面的代码,队列的同步执行是顺序执行的。这种顺序执行跟操作队列是串行还是并发是没有关系的。这些操作按着FIFO的方式进入队列中,每一个操作都会被等待执行直到前一个操作完成8,造成了这种顺序执行的现象。
现在我们整理一下队列同步执行的流程,如下图:
队列的异步:dispatch_async分析
测试代码
串行队列测试1
2
3
4
5
6let sQueue = DispatchQueue(label: "sQueue")
print(1)
sQueue.async { print("\(2):\(Thread.current)") }
print(3)
sQueue.async { print("\(4):\(Thread.current)") }
print(5)
执行结果1
2
3
4
51
3
5
2:<NSThread: 0x600000b884c0>{number = 4, name = (null)}
4:<NSThread: 0x600000b884c0>{number = 4, name = (null)}
并发队列测试
1 | let cQueue = DispatchQueue(label: "cQueue", attributes: [.concurrent]) |
执行结果
1 | 1 |
通过上面的测试代码我们可以知道:
- 队列异步执行任务的过程中,具备开辟新线程的能力。
- 非主队列的串行队列,会开辟一个新的线程,不会阻塞当前线程,所有任务有序执行。
- 并发队列会开辟多个线程,具体线程的个数有体统决定。所有任务是无序执行的。
入口函数:dispatch_async
dispatch_async的源码如下:
1 | void dispatch_async(dispatch_queue_t dq, void (^work)(void)) { |
dispatch_async主要将block从栈copy到堆上,或者增加引用计数,保证block在执行之前不会被销毁,另外_dispatch_call_block_and_release用于销毁block。然后调用dispatch_async_f。
dispatch_async_f函数的实现:
1 | void |
从上面的源代码中我们可以看出dispatch_async_f大致分为三种情况:
- 如果是串行队列,调用
dispatch_barrier_async_f函数; - 其他队列且有目标队列,调用
_dispatch_async_f2函数; - 如果是全局队列的话,直接调用
_dispatch_queue_push函数进行入队操作。
由于队列的异步执行任务的过程比较复杂,我们用一张图描述一下dispatch_async_f这个函数执行过程:
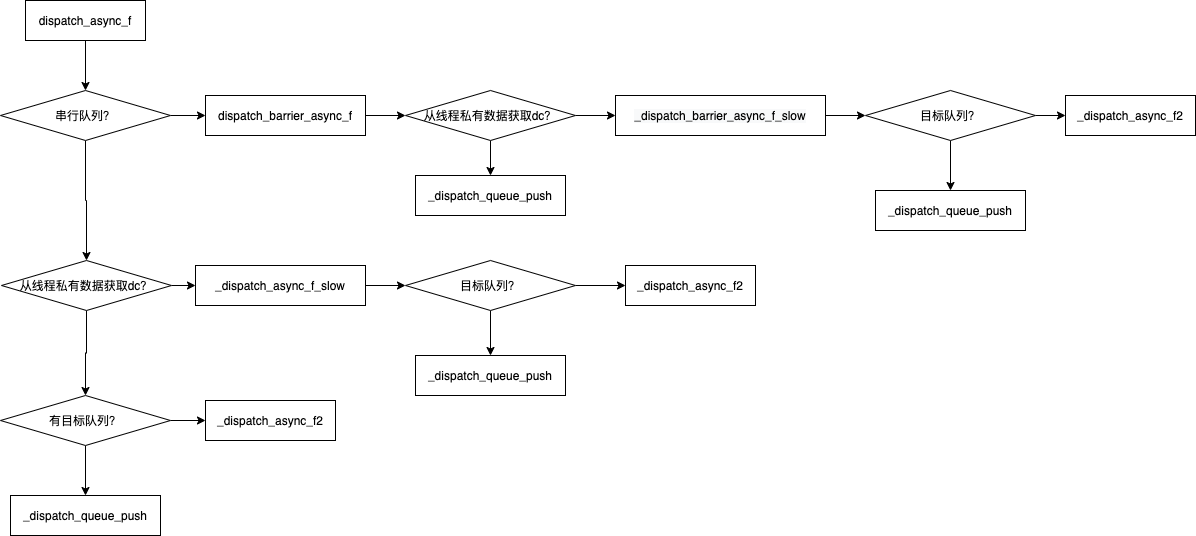
虽然上面分三种情况,它们最后执行都是_dispatch_queue_push或_dispatch_async_f2函数。另外_dispatch_async_f2函数其实也是在进行入队的操作。所以dispatch_async_f的本质就是执行_dispatch_queue_push函数来任务入队。
dispatch_continuation_t结构体
在看上述过程的源码时会涉及到dispatch_continuation_t这样的结构体,这个结构体的作用就是封装我们传入的异步block的任务。以dispatch_barrier_async_f函数的实现为例子:
1 | void dispatch_barrier_async_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func) { |
另外还需要注意下dispatch_continuation_t中do_vtable的赋值情况。
1 | // 串行队列异步或者使用dispatch_barrier_async函数会有一个DISPATCH_OBJ_BARRIER_BIT的barrier标记 |
在libdispatch全部标识符有四种:
1 |
从上面我们可以知道串行队列异步执行任务的时候,通过DISPATCH_OBJ_BARRIER_BIT这个标识符实现阻塞等待的。
任务入队:_dispatch_queue_push
_dispatch_queue_push是一个宏定义,它最后会变成执行_dispatch_queue_push_list函数。
1 |
_dispatch_trace_queue_push_list
1 | void _dispatch_trace_queue_push_list(dispatch_queue_t dq, dispatch_object_t _head, dispatch_object_t _tail) { |
_dispatch_queue_push_list
1 | void _dispatch_queue_push_list(dispatch_queue_t dq, dispatch_object_t _head, dispatch_object_t _tail) { |
_dispatch_queue_push_list_slow
1 | _dispatch_queue_push_list_slow(dispatch_queue_t dq, |
通过对异步任务入队的分析,我们可以知道,入队只是将任务一个一个以FIFO的顺序添加到队列中,那就是需要一个时间点去执行这些任务。
唤醒队列:_dispatch_wakeup
无论是同步还是异步中都调用了_dispatch_wakeup这个函数,这个函数的作用就是唤醒当前队列。
_dispatch_wakeup的源码:
1 | dispatch_queue_t _dispatch_wakeup(dispatch_object_t dou) { |
上面的代码中我们只看到了主队列和其他自定义队列的操作情况,但是没有全局队列的操作的情况,关于全局队列的唤醒的比较隐晦,针对全局队列的dx_probe(dou._do)的调用如下:
1 |
|
从上面的代码可以看出_dispatch_wakeup分为四种情况:
- 主队列调用
_dispatch_queue_wakeup_main; - 全局队列调用
_dispatch_queue_wakeup_global; - 其他队列向目标队列压入这个队列,继续做入队操作;
- 管理队列调用
_dispatch_mgr_wakeup,这里主要是为了dispatch_source而服务的。
_dispatch_queue_wakeup_main
_dispatch_main_queue_wakeup函数来唤醒主线程的Runloop,之前在《重拾RunLoop原理》中提到:
使用GCD异步操作的时候,我们在一个子线程处理完一些事情后,要返回主线程处理事情的时候,这时候需要依赖于RunLoop。
之前是控制台打印验证,现在我们在源码中亲自验证:
1 | void _dispatch_queue_wakeup_main(void) { |
_dispatch_queue_wakeup_global
1 | static bool |
队列的任务调度
主队列的任务调度:_dispatch_main_queue_callback_4CF
通过上面的源码分析,我们知道主队列在唤醒过程中会调用_dispatch_send_wakeup_main_thread函数,但是该函数的实现并没有开源这个函数的相关实现,似乎我们无法看出主队列的任务调度。通过打印函数调用栈我们可以看到主队列的任务调度是依赖_dispatch_main_queue_callback_4CF这个函数。
__CFRUNLOOP_IS_SERVICING_THE_MAIN_DISPATCH_QUEUE__之后调用_dispatch_main_queue_callback_4CF这个函数。
1 | // 处理主队列任务 |
主队列是一个串行队列,按顺序执行,因此没有并发的逻辑。主队列的任务调度就是顺序遍历,主队列唤起本次需要执行的dc,并进行任务执行,对于之后入队的任务,将放在下一轮的主队列唤醒中执行。这也是_dispatch_main_queue_drain函数的大致实现。
全局队列的任务调度:_dispatch_worker_thread2
全局队列通过_dispatch_queue_wakeup_global函数,将任务入队。然后调用 _dispatch_worker_thread2函数处理对应queue中的任务。
在_dispatch_worker_thread2的实现中有两个函数比较重要
_dispatch_queue_concurrent_drain_one函数;_dispatch_continuation_pop函数;
_dispatch_queue_concurrent_drain_one
_dispatch_queue_concurrent_drain_one函数主要处理了以下几件事情:
- 多线程竞争下的边界处理;
- 获取出队dc
- 再次唤醒全局队列
1 | static struct dispatch_object_s * |
这里解释下我对再次调用_dispatch_queue_wakeup_global唤醒全局队列的理解:
我们知道并发队列中的dc执行是并发的,所以每一次出队dc后检查一下全局队列,是否还有dc在队列中。如果有就再次通知需要再创建一个work queue处理队列中剩余的dc,然后重复上面的步骤,类似于一种递归的过程。当多个work queue同时处理多个dc的时候,就是我们看到异步效果。
_dispatch_continuation_pop
_dispatch_continuation_pop函数实现了对任务的处理。这些任务可能是异步任务、group任务、栅栏任务甚至可能就是队列。
1 | static inline void |
_dispatch_queue_invoke
1 | void |
现在我们整理一下队列异步执行的流程,如下图: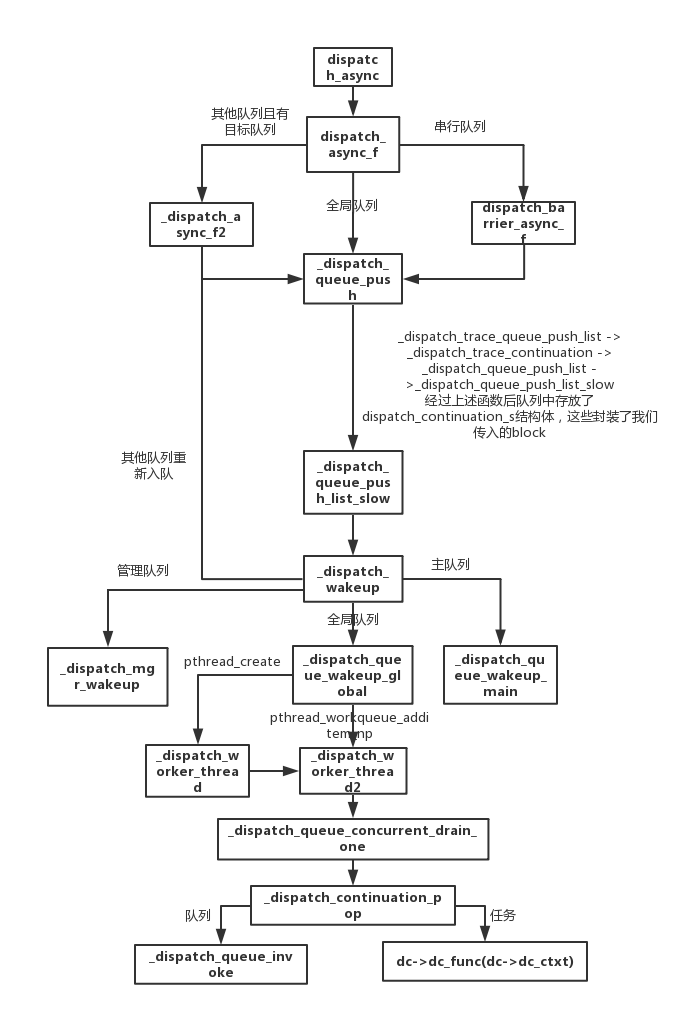
总结
- 队列与线程可以是多对一关系,一个线程上可以执行不同队列的任务,在主线程上一样适用。
- 队列操作与开启线程的关系:
- 串行队列同步执行任务,任务在当前线程中有序执行,如果前面的任务没有完成则可能会阻塞当前线程。
- 串行队列异步执行任务,开启一个线程,任务在新线程中有序执行,不会阻塞当前线程,新线程中的任务有序执行。
- 并发队列同步执行任务,不会开启新线程,任务在当前线程中有序执行,如果前面的任务没有完成则可能会阻塞当前线程。
- 并发队列异步执行任务,开启多个线程,具体数量由系统自己决定,任务在新开辟的线程中执行,不会阻塞当前线程,所有任务为无序执行。
- 主队列同步执行任务,死锁。
- 主队列异步执行任务,任务在主线程中有序执行,如果前面的任务没有完成则可能会阻塞当前线程。
- 队列的同步/异步决定是否具备开启线程的能力,队列的串行/并发决定处理任务的个数。
dispatch_queue通过结构体和链表,被实现为FIFO(先进先出)队列,无论串行队列和并发队列,都是符合FIFO的原则。两者的主要区别是:执行顺序不同,以及开启线程数不同。dispatch_sync函数一般都在当前线程执行,利用与线程绑定的信号量来实现串行。dispatch_async分发到主队列的任务由Runloop处理,而分发到其他队列的任务由线程池处理。Block并不是直接添加到队列上,而是先构成一个
dispatch_continuation结构体。结构体包含了这个Block还有一些上下文信息。队列会将这些dispatch_continuation结构体添加队列的链表中。无论这些队列是什么类型的,最终都是和全局队列相关的。在全局队列执行Block的时候,libdispatch从全局队列中取出dispatch_continuation,调用pthread_workqueue_additem_np函数,将该全局队列自身、符合其优先级的workqueue信息以及dispatch_continuation结构体的回调函数传递给参数。pthread_workqueue_additem_np函数使用workq_kernreturn系统调用,通知workqueue增加应当执行的项目。根据该同志,XNU内核基于系统状态判断是否要生成线程。如果是overcommit优先级的全局队列workqueue则会始终生成线程。workqueue的线程执行pthread_workqueue函数,该函数调用libdispatch的回调函数。在该函数中执行加入到dispatch_continuation的BlockGCD死锁是队列导致的而不是线程导致,原因是
_dispatch_barrier_sync_f_slow函数中使用了线程对应的信号量并且调用wait方法,从而导致线程死锁。关于栅栏函数
dispatch_barrier_async适用的场景队列必须是用DISPATCH_QUEUE_CONCURRENT属性创建的队列,而使用全局并发队列的时候,其表现就和dispatch_async一样。原因:dispatch_barrier_async如果传入的是全局队列,在唤醒队列时会执行_dispatch_queue_wakeup_global函数,其执行效果同dispatch_async一致,而如果是自定义的队列的时候,_dispatch_continuation_pop中会执行dispatch_queue_invoke。在while循环中依次取出任务并调用_dispatch_continuation_redirect函数,使得block并发执行。当遇到DISPATCH_OBJ_BARRIER_BIT标记时,会修改do_suspend_cnt标志以保证后续while循环时直接goto out。barrier block的任务执行完之后_dispatch_queue_class_invoke会将do_suspend_cnt重置回去,所以barrier block之后的任务会继续执行。