之前已经介绍了dispatch_semaphore的底层实现,dispatch_group的实现是基于前者的。在看源码之前,我们先看一下我们是如何应用的。假设有这么场景:有一个A耗时操作,B和C两个网络请求和一个耗时操作C当ABC都执行完成后,刷新页面。我们可以用dispatch_group实现。关键如下:
1 | - (void)viewDidLoad { |
接下来我们根据上面的流程来看一下dispatch_group的相关API
dispatch_group_create
1 | dispatch_group_t |
dispatch_group_create其实就是创建了一个value为LONG_MAX的dispatch_semaphore信号量
dispatch_group_async
1 | void |
dispatch_group_async只是dispatch_group_async_f的封装
dispatch_group_async_f
1 | void |
从上面的代码我们可以看出dispatch_group_async_f和dispatch_async_f相似。dispatch_group_async_f多了dispatch_group_enter(dg);,另外在do_vtable的赋值中dispatch_group_async_f多了一个DISPATCH_OBJ_GROUP_BIT的标记符。既然添加了dispatch_group_enter必定会存在dispatch_group_leave。在之前《深入理解GCD之dispatch_queue》介绍_dispatch_continuation_pop函数的源码中有一段代码如下:
1 | _dispatch_client_callout(dc->dc_ctxt, dc->dc_func); |
所以dispatch_group_async_f函数中的dispatch_group_leave是在_dispatch_continuation_pop函数中调用的。
这里概括一下dispatch_group_async_f的工作流程:
- 调用
dispatch_group_enter; - 将block和queue等信息记录到
dispatch_continuation_t结构体中,并将它加入到group的链表中; _dispatch_continuation_pop执行时会判断任务是否为group,是的话执行完任务再调用dispatch_group_leave以达到信号量的平衡。
dispatch_group_enter
1 | void |
dispatch_group_enter将dispatch_group_t转换成dispatch_semaphore_t,并调用dispatch_semaphore_wait,原子性减1后,进入等待状态直到有信号唤醒。所以说dispatch_group_enter就是对dispatch_semaphore_wait的封装。
dispatch_group_leave
1 | void |
从上面的源代码中我们看到dispatch_group_leave将dispatch_group_t转换成dispatch_semaphore_t后将dsema_value的值原子性加1。如果value为LONG_MIN程序crash;如果value等于dsema_orig表示所有任务已完成,调用_dispatch_group_wake唤醒group(_dispatch_group_wake的用于和notify有关,我们会在后面介绍)。因为在enter的时候进行了原子性减1操作。所以在leave的时候需要原子性加1。
这里先说明一下enter和leave之间的关系:
dispatch_group_leave与dispatch_group_enter配对使用。当调用了
dispatch_group_enter而没有调用dispatch_group_leave时,由于value不等于dsema_orig不会走到唤醒逻辑,dispatch_group_notify中的任务无法执行或者dispatch_group_wait收不到信号而卡住线程。dispatch_group_enter必须在dispatch_group_leave之前出现。当
dispatch_group_leave比dispatch_group_enter多调用了一次或者说在dispatch_group_enter之前被调用的时候,dispatch_group_leave进行原子性加1操作,相当于value为LONGMAX+1,发生数据长度溢出,变成LONG_MIN,由于value == LONG_MIN成立,程序发生crash。
dispatch_group_notify
1 | void |
dispatch_group_notify是dispatch_group_notify_f的封装,具体实现在后者。
dispatch_group_notify_f
1 | void |
所以dispatch_group_notify函数只是用链表把所有回调通知保存起来,等待调用。
_dispatch_group_wake
1 | static long |
_dispatch_group_wake主要的作用有两个:
调用semaphore_signal唤醒当初等待group的信号量,使得dispatch_group_wait函数返回。
获取链表,依次调用dispatch_async_f异步执行在notify函数中的任务即Block。
到这里我们已经差不多知道了dispatch_group工作过程,我们用一张图表示: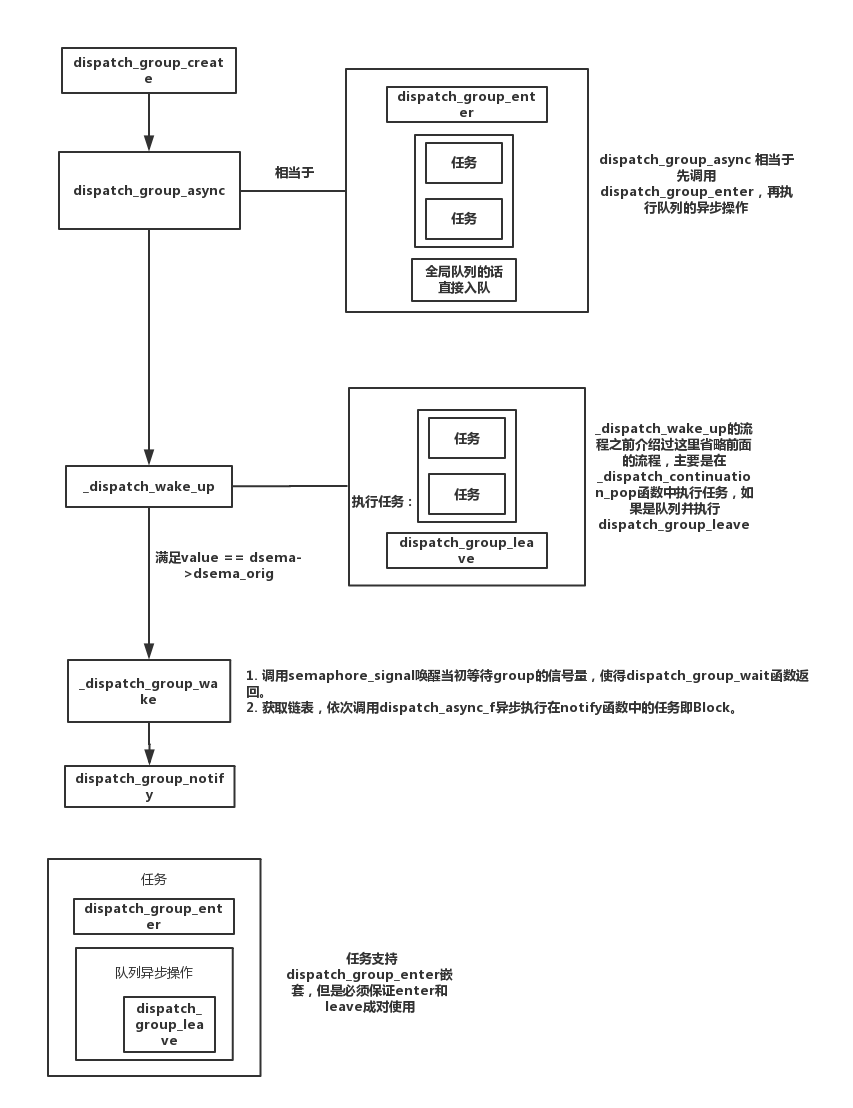
dispatch_group_wait
1 | long |
dispatch_group_wait用于等待group中的任务完成。
_dispatch_group_wait_slow
1 | static long |
从上面的代码我们发现_dispatch_group_wait_slow和_dispatch_semaphore_wait_slow的逻辑很接近。都利用mach内核的semaphore进行信号的发送。区别在于_dispatch_semaphore_wait_slow在等待结束后是return,而_dispatch_group_wait_slow在等待结束是调用_dispatch_group_wake去唤醒这个group。
总结
dispatch_group是一个初始值为LONG_MAX的信号量,group中的任务完成是判断其value是否恢复成初始值。dispatch_group_enter和dispatch_group_leave必须成对使用并且支持嵌套。如果
dispatch_group_enter比dispatch_group_leave多,由于value不等于dsema_orig不会走到唤醒逻辑,dispatch_group_notify中的任务无法执行或者dispatch_group_wait收不到信号而卡住线程。如果是dispatch_group_leave多,则会引起崩溃。